May 30, 2025
Smarter APIs, Cleaner UI, and Better Dev Ergonomics
Key Highlights
Support for Path Parameters in HTTP Sources: Infactory’s HTTP data source integration now allows dynamic path parameters in API endpoint URLs, enabling more flexible queries (e.g. inserting an ID segment into the URL path). This gives developers finer control when connecting to REST endpoints without resorting to query strings or workarounds.
Better Handling of Large API Responses: We improved how the platform deals with very large JSON schemas returned by API endpoints. The system now automatically measures the size of an API response’s schema and adjusts validation strictness for oversized schemas, preventing errors when you connect to data sources that return massive or deeply nested JSON data.
UI Enhancements in Data Source Management: We refined parts of the console UI to make configuring data sources easier. The Database (SQL/CosmosDB) connection dialog was reorganized for clarity – the Description field now appears below the Name with a clear separator for better visual hierarchy. Additionally, if a query name in the sidebar is too long and gets truncated with an ellipsis, you can hover on it to reveal the full name in a tooltip for improved readability.
Fixes & Improvements
Fixed several issues with SQL data loading parameters and data type inference for SQL connectors.
Restored the ontology generation step that was inadvertently skipped during debugging, so new connections generate ontologies as expected.
Reorganized the Database and CosmosDB “Connect” dialog for better UX (Description field moved below Name with a visual separator).
Added hover tooltips for truncated query names in the sidebar to display the full query title on mouseover.
Improved handling of very large API schemas by automatically detecting schema size and relaxing strict validation rules for huge schemas.
May 19, 2025
Smarter Onboarding, Faster Setup

Major Highlights
Data Autogeneration Guidance – When Infactory auto-generates data source queries, it now provides helpful descriptions and user guidance along with the queries. This improvement makes the automatically generated queries easier to understand and refine, helping you get to correct results faster.
cURL Paste for HTTP Sources – The HTTP API data source dialog now supports pasting a cURL command directly. You can drop in a
curlcommand and Infactory will auto-fill the method, URL, headers, and body, along with a new UI hint in the dialog. This makes connecting to HTTP APIs quicker and less error-prone.
Fixes, Improvements, API
Team Invitations: Fixed an issue where invited users signing up would create a new team instead of joining the existing team. Invited members now correctly join the original team on organization signup. This ensures smoother onboarding for team invites without duplicate teams being created.
May 12, 2025
Smoother Onboarding with Better Examples

Major Highlights
Smoother Onboarding and 160+ New Integrations – We improved the onboarding experience by fixing bugs in our example projects, making it easier to get started with Infactory. We also added over 160 new connectors—including databases, CRMs, ticketing systems, accounting platforms, and more—so you can plug Infactory into the tools your business already uses.
Fixes, Improvements, API
Fixed a bug that prevented the “Hello World” demo from running correctly.
Updated the built-in IMDb example project with improved content and queries.
Added 160+ new data source connectors, including PostgreSQL, MySQL, Salesforce, HubSpot, QuickBooks, Asana, and more
May 7, 2025
Under the Hood Improvements for a Faster, More Reliable Infactory
Major Highlights
This week we focused on behind-the-scenes enhancements to improve Infactory’s stability and performance. A critical integration update to our data analysis engine has significantly boosted reliability, ensuring smoother operation during complex queries. While there were no major UI changes, these foundational improvements pave the way for a faster and more robust user experience.
Fixes, Improvements, API
Enhanced analysis engine integration – Improved the internal integration of our data processing engine for faster query execution and more reliable results in complex workflows.
Stability improvements in data handling – Refined how the system stores and processes data behind the scenes, increasing overall stability and reducing potential errors during heavy data operations.
Apr 30, 2025
Faster Connections, Safer Queries

Major Highlights
In the last two weeks of April, the Infactory team delivered several improvements focused on user experience, reliability, and security. The data source connection workflow was streamlined – connecting to HTTP APIs, PostgreSQL, or CosmosDB now opens a configuration dialog in place instead of navigating away, making it faster and more intuitive to add new data sources. Query auto-generation also became smoother and non-blocking: the app now polls for results in the background (up to \~40 seconds) with real-time progress updates, so you can continue working while your query is being generated. We also fixed an important security bug to ensure sensitive information never leaks – database connection errors will no longer display passwords or credentials in plain text. These changes make Infactory safer and more convenient, letting you integrate data sources and build queries with greater confidence and ease.
Fixes, Improvements, and API
Credentials Privacy: Error messages from failed data-source connections no longer expose passwords or secrets in logs.
Non-blocking Query Generation: Improved query auto-generation with a 40-second polling mechanism and live UI updates, so large AI-generated queries no longer freeze the interface.
Accurate Data Transformations: Fixed a bug in the **quantile** calculation function to ensure correct results during data processing.
UI Stability: Eliminated a visual “flash” that would occur when viewing certain query results (no more flicker in the query list/Explorer view).
Each of these fixes and enhancements contributes to a more seamless and secure experience for Infactory users – from connecting new databases to trusting the platform with your data and credentials. Enjoy the updated workflow and smoother performance!
Apr 4, 2025
SDKs, project portability, and faster starts
This cycle we focused on making Infactory easier to adopt, easier to scale, and a whole lot smoother to debug. From brand-new SDKs and automatic API generation to a better way to share or migrate entire projects.
🧪 Example projects to help you hit the ground running
We’ve added our first public example project (IMDB) so new users can explore Infactory with real data and working queries right out of the box. No setup required—just open it, explore how things are built, and start editing.

More examples coming soon!
🔄 Import & export entire projects
You can now export and re-import projects with full fidelity—credentials, data lineage, and S3 paths included. Whether you’re duplicating environments, migrating between deploy targets, or setting up fresh sandboxes, the new system makes it simple and safe.
🐍📦 SDKs for Python and JavaScript
We launched three SDKs to make Infactory work wherever you do:
• Python SDK — Automate everything from CLI or backend
• TypeScript SDK — Drop into your web apps
Everything from login to running queries to publishing APIs is now one command away.
Fixes, Improvements, and API
• Fully revamped project export/import with credential, lineage, and storage handling
• Added IMDB example project to help new users start building instantly
• Improved deployment reliability with build retries and better lockfile handling
• Debugging is now easier with error traces and surfaced failures in the Build UI
• Auth now applied consistently across all APIs, not just completions
• Extended CLI testing for end-to-end coverage across all major features
• Added support for ARM builds and minikube-based local deployments
• Cleaned up GitHub Actions runners and streamlined CI environments
• Slack Connect auto-invites + waitlist improvements for smoother onboarding
Mar 7, 2025
Smarter Deployments with Completions UI
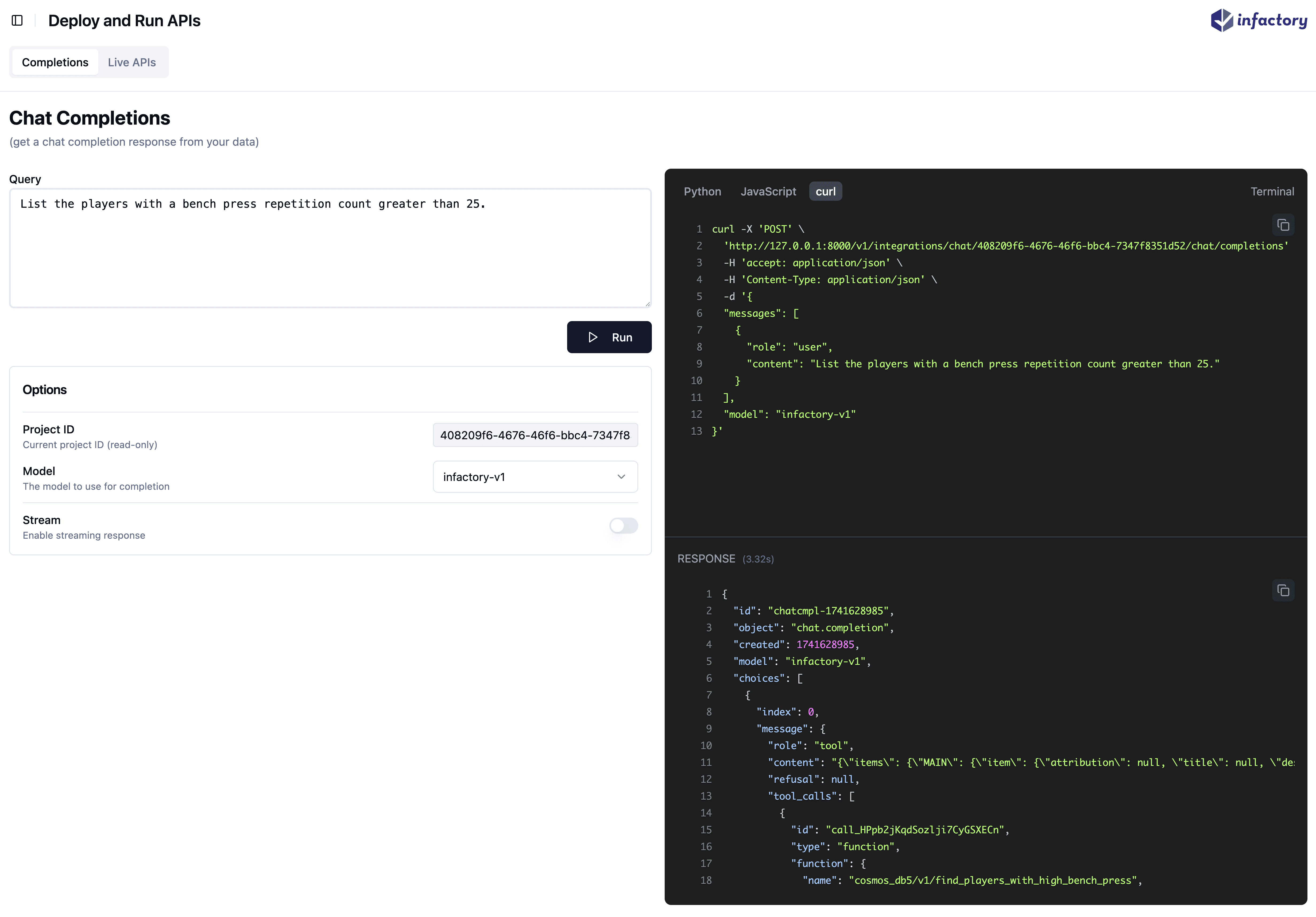
We've enhanced the Deploy Page with a completions UI, making it easier and faster to interact with deployment configurations. This update improves user experience by offering better guidance and reducing friction when setting up deployments.
Better API Recommendations
Our API Recommendation System is now smarter! We added in-memory vector similarity to function_call.py, improving the way we suggest APIs based on past interactions. This makes our system more efficient at delivering relevant recommendations.
Cosmos DB Integration
We've integrated Cosmos DB queries, making it easier to work with large-scale, distributed databases. This enhancement allows for seamless querying and better data management, improving overall system performance.

Chat Completions API Compatibility
We introduced a chat completions-compatible endpoint, aligning with OpenAI’s API format. This makes it easier for developers to integrate our chat-based functionalities with existing AI-driven workflows.
Fixes & Improvements
API & Infrastructure
Added Milvus as a vector store backend.
Exposed the Live API directly in the Deploy Page.
Added
webui-tools.jsonandtools.pyas new API endpoints.
User Experience & Bug Fixes
Fixed SQL data object creation when selecting a table instead of writing raw SQL.
Ensured the Validate button matches the Connect button color for visual consistency.
Addressed a "No datasources connected" error in the Deploy Page.
Improved schema slot handling for query programs, simplifying developer workflows.
Security & Deployment Enhancements
Reconfigured Cloudflare SSL, ensuring secure deployments.
Created stronger config maps for each customer deployment.
Automated deployment of frontend, backend, and database backups for each customer.
Feb 21, 2025
PostgreSQL Connectivity & Performance Upgrades
We’re excited to announce that Infactory now supports direct connections to PostgreSQL databases! This unlocks a world of possibilities, making it easier to query, analyze, and integrate your data seamlessly. Along with this, we’ve introduced a Custom SQL tab on the PostgreSQL connection page, giving you more flexibility in writing and running SQL queries directly.

Additionally, we've made improvements to query autogeneration when connecting to PostgreSQL, streamlining the experience for users who want quick insights without manually crafting queries.
Fixes & Improvements
Performance Optimization
Updated CloudWatch dashboards & alarms for better monitoring of our infrastructure.
Switched runner hosts & backend API instances to more cost-effective AWS instance types.
Enabled dynamic instance selection in Terraform to optimize costs (e.g., Spot instances for development).
Implemented automatic Docker image pruning for self-hosted runners to keep environments clean.
UX/UI Enhancements
Scrollable query lists for a smoother experience.
Aligned query editor and chat window styles for consistency.
Refined color scheme in the query editor to match Infactory’s design.
Deploy button fixes – resets state after clicking and is now positioned more intuitively.
Bug Fixes
Fixed S3 chunking issue to optimize large file uploads.
Resolved CSV upload flow issues – improving performance and security.
Fixed query execution errors that caused subsequent runs to fail.
Addressed progressive chart breakage and improved auto-generated query quality.
With PostgreSQL integration and a host of performance upgrades, Infactory is now more powerful and efficient than ever. Let us know what you think! 🚀
Feb 16, 2025
Improved User Experience and Robust Security Enhancements
Feature Updates
Project Management: Enhanced Editing and Syncing
Streamline your project management with new editing capabilities. Users can now effortlessly update project details, with the added benefit of conversation syncing for seamless transitions between projects. The new ProjectForm component simplifies the creation and editing processes, boosting productivity and user satisfaction.
Advanced Authentication with RBAC and Casbin
Upgrade your security protocols with role-based access control (RBAC) and Casbin integration. This new feature enhances security by managing user permissions effectively, ensuring that only authorized users can access specific API endpoints.
Enhancements & UX Improvements
Data Visualization: Customizable Charting
Experience improved data visualization with live chart customization. Users can now toggle series data on and off, allowing for more personalized and meaningful data exploration.
Enhanced Code Editor Usability
Enjoy a more intuitive coding experience with enhancements to the Code Editor. Unwanted text patterns are now automatically cleaned, and horizontal scrolling is introduced for better readability and usability.
File Upload Improvements
The FileUpload component now restricts uploads to CSV files only, ensuring data consistency. Users will receive toast notifications for any errors, enhancing the overall user experience.
Performance & Reliability
Panel Size Management for Consistent Layouts
Manage your workspace efficiently with the new panel size management feature. This update ensures consistent panel resizing across various layouts, providing a more organized and user-friendly interface.
Improved DataFrame Caching
Boost performance with local DataFrame caching. This enhancement reduces loading times, ensuring that data is readily available and improving overall application responsiveness.
Bug Fixes
Resolved an issue where downloading charts was not functioning correctly, ensuring reliable data export capabilities.
Fixed a problem with authentication in development environments, re-enabling user authentication requirements for improved security.
Corrected a bug that prevented proper chart rendering in the DataFrame Renderer, ensuring accurate and reliable data visualization.
Feb 14, 2025
A More Reliable and Intuitive Infactory

This cycle, we focused on making Infactory more stable, secure, and user-friendly. We improved authentication, enhanced error handling, and fixed key UI/UX issues. Additionally, we made major improvements to our API and deployment processes to ensure smoother workflows.
Highlights
Role-Based Authentication (RBAC)
We introduced role-based authentication to enforce access control. Each user now has anorg_adminrole by default, limiting CRUD operations to their organization and preventing cross-organization data access.Smarter Page Titles
Instead of falling back to a generic phrase like "Find knowledge in your data", pages now use more descriptive and relevant titles.Improved Cloud Deployment
Provisioned S3 buckets for deployment logs, improving logging and debugging for on-premise installations.
Migrated Cloudflare DNS management to Terraform, allowing for more structured and reproducible infrastructure updates.
Landing Page Revamp
We launched a new Landing Page, refining the first touchpoint with users and ensuring a smoother onboarding experience.
Fixes & Improvements
User Experience & Interface
Fixed Infactory Assistant overflowing the screen in the Build page.
Removed unnecessary console logs in chat, significantly improving performance.
Syntax highlighter no longer re-renders on every keystroke, reducing lag.
The query program editor now removes redundant code markers on first insertion.
Deployment & Infrastructure
Updated CloudWatch alarms with longer-duration triggers for more reliable alerting.
Fixed an intermittent network error affecting Docker builds.
Resolved authentication issues in the dev environment to restore access control.
Prevented running/deploying an empty query program, ensuring valid input.
Improved API routing and request handling for better performance.
Data & Query Handling
Fixed an issue where deployed query program buttons disappeared after deployment.
Improved metadata extraction from query programs for better query generation.
Fixed chart downloads, ensuring users can properly export visualized data.
Added live chart customization options, giving users more control over how data is displayed.
Security & Access Control
Fixed Invalid AZP Claim errors on authentication, ensuring smoother logins.
Removed all outdated tests from GitHub since they were no longer functional.
Other Improvements
Updated README with a Quick Start Guide for easier setup.
Renamed CRUD directories and components to better reflect their purpose.
Integrated APIGen Dataset for enhanced API recommendation functionality.
Thanks for your continued feedback! More exciting updates are on the way 🚀.
Feb 9, 2025
Enhanced API Flexibility and Frontend Refinements
Feature Updates
Fivetran Integration: Expanding Data Connectivity
We've introduced Fivetran integration into the frontend, significantly enhancing your data integration capabilities. This allows for seamless data synchronization and management across your projects. Now, you can set default sizes for ResizablePanel components, providing a more intuitive and flexible user experience.
Improved Explore Experience: More Intuitive Data Interactions
Enhancements have been made to the explore page, including the addition of a fallback function to improve UI interactions and rendering of tables and charts. These changes ensure a smoother, more reliable exploration experience.
API Enhancements: Better Routing and Flexibility
We've updated our API to support both slashed and unslashed URL paths, enhancing flexibility and consistency in API usage. This change simplifies routing and improves user experience by allowing more intuitive API interactions.
Enhancements & UX Improvements
Streamlined Message Handling
We have improved message handling by introducing error checks and removing redundant message entries. This ensures a cleaner and more efficient chat history, allowing you to focus on meaningful interactions.
Refined Example Programs
Our example programs have been updated with new fixes and enhancements, ensuring they are more comprehensive and easier to use. This update includes re-generated examples for baseball and Posthog integrations, providing better insights and learning opportunities.
Performance Optimization: Cleaner Console Logs
Unnecessary console log statements have been removed, reducing log clutter and improving performance. This results in a faster and more responsive streaming text experience.
Bug Fixes
Resolved an issue where CSV uploads were not sending data to S3, improving data upload reliability.
Fixed JSON formatting bugs to ensure data integrity and prevent processing errors.
Addressed issues with conversation history not displaying completely, ensuring all relevant data is visible.
Developer Experience
Enhanced SDK Error Handling
Improved error handling in our SDK now passes specific 4xx errors back to the frontend, allowing for more precise debugging and user feedback. This ensures that issues are caught and addressed more efficiently, enhancing overall reliability.
Codebase Optimization
Various refactoring efforts have been undertaken to streamline our codebase, including the removal of redundant routes and unused code. These improvements aid in maintainability and readability, making it easier for developers to work with the code.
These changes aim to enhance your experience by providing more robust features, improving interaction quality, and ensuring smoother operation across our platform.
Feb 2, 2025
Enhanced Fivetran Integration and Improved Query Interface
Feature Updates
Fivetran Integration: Seamless Data Connectivity
The integration with Fivetran has been significantly enhanced, enabling seamless data connectivity directly within your dashboard. This update includes the addition of connector detail pages and improved API routes, providing users with a more intuitive and efficient data management experience. The integration also supports real-time status updates and enhanced error handling, ensuring smoother operations and better data visibility.
Query Program Enhancements: Streamlined Execution and Management
The query program interface has been upgraded to support execution time tracking and refined result handling. These improvements simplify query execution and enhance user experience by providing more detailed feedback and better management of query states. Additionally, a new context menu for query tabs has been introduced, offering flexible tab management options for a clutter-free workspace.
Enhancements & UX Improvements
Custom Formatting and Data Model Updates
The editor now supports custom formatting for new data types, bringing back the accept/reject button experience for a more interactive and user-friendly interface. Data models have been updated to include new fields, improving data handling and integration consistency across the platform.
Performance & Reliability
Cleaner Shutdowns and Optimized Data Retrieval
A new trap has been added for cleaner shutdowns, ensuring system stability and integrity during operations. SQL queries have been optimized for improved readability and performance, enhancing data retrieval processes and overall application reliability.
Bug Fixes
Fixed data source upload issues by deprecating outdated column specifications, ensuring smoother data handling.
Resolved a bug in the chat graph that improved explanation generation, enhancing functionality on the explore page.
Developer Experience
Improved API and Code Management
The API management system has been upgraded to include optimistic updates and better state integration, streamlining developer workflows. Code refactoring across various components has improved readability and maintainability, creating a more robust development environment.
Jan 26, 2025
Enhanced Chat Functionality and Query Improvements
Feature Updates
Enhanced Chat Functionality with Explanations
We've added a new component to the chat system that provides detailed explanations for function responses. This enhancement ensures that users have clear context and understanding of the chat interactions, significantly improving the user experience when engaging with automated tools.
PostHog Query Deployment and Enhancements
A comprehensive set of queries has been deployed for PostHog, enhancing data analysis capabilities. These changes include updates to funnel queries and improvements in test accuracy. Note that the new queries require regeneration due to non-backwards compatible changes, ensuring more robust data insights.
Enhancements & UX Improvements
Improved Vertical Scroll in Build Pane
We've implemented vertical scrolling within the build pane chat answer section, enhancing navigability and user interaction with chat responses, particularly useful during in-depth discussions and long responses.
Dashboard Integration in App Sidebar
The in-app sidebar now features a dedicated dashboard, providing quick access to key metrics and navigation options. This update streamlines user interaction with core app functionalities, boosting productivity and ease of use.
Bug Fixes
Corrected a spelling inconsistency from "explaination" to "explanation" across multiple files, enhancing clarity and consistency in the chat module.
Addressed a glitch in the
test_stocks_general_005.pywhere tests were erroneously stuck in a "smoke test" mode, ensuring smoother test operations.Fixed issues with PostHog queries involving sliding time windows, resolving errors and improving query reliability.
Developer Experience
Code Cleanup and Refactoring
Significant code cleanups and refactoring were undertaken to improve maintainability and readability of the chat components and related API routes. This includes streamlining message rendering logic and enhancing the format_message_endpoint function, making it easier for developers to navigate and extend the codebase.
Jan 19, 2025
Enhanced Explore Page and Improved Query Handling
Feature Updates
Explore Page Revamp for Beta Launch
The Explore page has undergone significant updates in preparation for its beta launch. This includes improved chat functionality with enhanced conversation context, real-time status updates, and a more intuitive layout. Users will experience smoother interactions and better data representation, thanks to the integration of a conversation graph model.
Multiple Dataframe Query Support
Queries now support multiple dataframes, enhancing the flexibility and power of data analysis. This new feature allows users to execute complex queries across various data sources, making the platform more robust and versatile.
Improved Slot Filling with Generous Acceptance
The system now generously accepts array-like strings and taxon leaf values for slot filling, simplifying data input processes. This change ensures a more seamless integration of data, reducing errors and improving overall efficiency.
Enhancements & UX Improvements
Enhanced Loading Animations
Loading animations have been refined for a more visually appealing user experience. This improvement helps users better understand the system's processing status, reducing uncertainty during wait times.
Frontend Interface Tweaks
Several small frontend fixes have been implemented, including inline "Thinking..." badges and improved button aesthetics in chat components. These updates ensure a cleaner, more intuitive user interaction with the platform.
Console Logging Improvements
Console outputs have been streamlined by replacing unnecessary log statements with appropriate log levels. This cleanup enhances code readability and helps developers quickly identify potential issues during local deployments.
Bug Fixes
Resolved issues with stray text in posthog query examples, ensuring cleaner and more accurate query results.
Fixed glitches in the Explore page that previously affected data scrolling and rendering.
Addressed errors in the posthog query integration, ensuring smoother data visualization in AG Grid and AG Chart components.
These updates collectively enhance both the user and developer experience, making the platform more efficient, responsive, and user-friendly.
Jan 12, 2025
Robust Data Handling and Enhanced API Flexibility
Feature Updates
Improved Datetime Handling for Consistent Data Processing
We have standardized our approach to datetime handling across the system, ensuring uniformity and reducing errors in query operations. This change enhances data integrity and reliability, especially in complex data integrations.
Simplified Schema Management with Direct Dataset Naming
ColumnT and SchemaT names now leverage CSV filenames directly, providing clearer and more intuitive schema management. This change streamlines processes and reduces reliance on AI-generated names for improved clarity and usability.
Enhanced API Documentation Flexibility
API documentation can now dynamically determine host and scheme from request headers, making the documentation more adaptable and accurate across various deployment environments.
Enhancements & UX Improvements
Robust CSV Upload and Data Inference Capabilities
Our CSV upload process has been fortified with improved data inference, particularly for handling complex datasets like posthog data. This ensures more accurate data sampling and better performance in data handling tasks.
Improved Query Handling in Workshop Components
We've refactored various components in our workshop interface, enhancing message handling, formatting, and state management for a smoother user experience when working with complex queries.
Performance & Reliability
ConnectorX Dependency Integration
The addition of ConnectorX as a dependency improves data connectivity and transfer speeds, enhancing overall system performance for data-intensive tasks.
Dynamic Runnable Checks in Query Programs
Query programs now skip steps with unfilled slots, optimizing performance by avoiding unnecessary computations. This ensures that only fully prepared operations are executed, improving efficiency.
Bug Fixes
Resolved issues with OpenAPI documentation visibility in production by updating environment configurations and host parameter handling.
Fixed an error in ask_dataline.py to simplify error handling and improve system stability.
Jan 5, 2025
Enhanced Query Handling and Improved Job Management
Feature Updates
Robust Job Management System
A comprehensive job management system has been implemented, allowing better submission, status updates, and metrics tracking. This new feature streamlines job-related API requests and enhances the overall workflow for managing job processes.
Expanded Query Example Library
We've added a multitude of new query examples across datasets such as ads, coffee, stocks, and baseball. These examples are designed to improve the machine learning model's ability to generate accurate and relevant queries.
Enhancements & UX Improvements
Query Program Error Reporting
Basic error reporting has been introduced for failed query program generations. This enhancement helps users identify and troubleshoot issues more effectively, paving the way for smoother query development.
Improved Query Program Prompts
The query program generation process has been refined by fixing misleading prompts, reducing errors in generated queries. This change ensures more accurate query development for users.
Enhanced Table Formatting
We've made visual improvements to result tables, including width adjustments and better rounding of floats. These enhancements provide a cleaner and more readable presentation of data outputs.
Streamlined URL Handling in FastAPI
FastAPI apps now feature an updated configuration that prevents automatic redirection of URLs with trailing slashes. This change enhances URL management and improves user navigation experiences.
Bug Fixes
Resolved an issue where non-existent columns were being included in query programs due to confusing prompts, improving the accuracy of query generation.
Dec 29, 2024
Comprehensive Flow Cleanup and Enhanced Query Management
Feature Updates
Improved Query Deletion and Management
The soft delete capabilities for query programs have been enhanced with error handling and user feedback. Users can now unpublish query programs before deletion, ensuring smoother management and better control over their query lifecycle.
Enhanced Conversation Creation and Management
Introducing new functionality to create conversations directly from the Explore Layout. This update includes a streamlined interface for starting conversations, enhanced layout presentation, and a new icon to indicate a "no conversation" state, making user interactions more intuitive and engaging.
Simplified Structured Data Handling
The handling of structured data has been simplified by removing the "df_" prefix from query program methods and eliminating the use of confusing GeneralColumnT types. These changes streamline the query writing process, making it more intuitive and consistent.
Enhancements & UX Improvements
UI Consistency and Readability
Numerous improvements have been made to ensure a consistent and readable UI. This includes better handling of text areas post-navigation, improved spacing in components, and enhanced feedback messages during query actions. These changes contribute to a smoother and more cohesive user experience across the platform.
Layout and Usability Enhancements
The Explore Layout now features conversation filtering and selection functionalities, along with search inputs and tooltips for creating new conversations. These enhancements aim to improve accessibility and usability, allowing users to navigate and manage their conversations more effectively.
Bug Fixes
Addressed timing issues with textarea focus after navigation, improving user experience during data entry processes.
Resolved issues with incorrect item rendering in the renderer component, enhancing reliability and user feedback.
Fixed formatting issues and ensured consistent order in sidebar navigation, improving overall interface consistency.
Developer Experience
Type Safety and Compatibility Improvements
Updated TypeScript and related type definitions to the latest versions, improving type safety and compatibility across the project. This ensures better maintainability and reduced potential for runtime errors.
Codebase Cleanup and Optimization
Removed obsolete code and unused version history data, reducing clutter and improving repository maintainability. These optimizations contribute to a cleaner and more efficient development environment.
Dec 22, 2024
Enhanced Chat Features and Query Program Improvements
Feature Updates
Chat with Your Data: Screen and Flow Improvements
Interact with your data more smoothly with enhanced chat functionalities. The chat screen now better manages conversations, implements streaming responses for real-time communication, and supports tool calls, providing a more robust interactive experience.
Query Program Generation: Consistency and Optimization
We've reworked our query program generation for enhanced clarity and reduced redundancy. This update ensures that slot generation is more consistent, improving the overall performance of query handling.
Enhancements & UX Improvements
Slot Management: Enhanced Flexibility
Slot management received a significant upgrade, allowing for more consistent type validation and flexibility in slot creation. This change ensures that slots are generated more accurately, adhering to schema constraints.
Improved Program Flow and Naming Consistency
The program generation flow has been refined to use consistent patterns across functions, reducing confusion and allowing for smoother integration and future updates.
Performance & Reliability
Aggregation Methods: Simplified and Streamlined
The aggregation process has been consolidated into a single, more intuitive method. This simplification reduces errors and makes it easier for our logic model to handle complex grouping and aggregation tasks.
Chat Flow Parsing: Enhanced Accuracy
Parsing improvements in the chat flow ensure that only the most relevant tool call information is processed, reducing confusion and improving the reliability of ongoing conversations.
Bug Fixes
Resolved deprecation warnings from Pydantic, enhancing compatibility and future-proofing our codebase.
Addressed issues with slot filling, ensuring that slots are correctly managed as lists rather than dictionaries.
Fixed a bug that prevented some column functions from executing correctly, improving query reliability.
Developer Experience
Codebase Cleanup and Consistency
Our codebase has undergone significant cleanup, improving readability and maintainability. This includes standardizing naming conventions and refactoring redundant code segments for a cleaner development environment.
Dec 15, 2024
Comprehensive API Enhancements and Query System Optimizations
Feature Updates
End-to-End API Publishing and Customization
Streamline your API management with robust new features for creating, editing, and deleting APIs. Enhanced validation ensures reliable endpoint configurations, while optional hard delete functionality allows for permanent API removal when necessary. These updates simplify API lifecycle management and improve consistency across your projects.
Custom API Editor in Frontend
Introducing a customizable API editor interface for frontend users. This new tool enhances how you interact with API definitions directly from the UI, allowing for more intuitive API management and quicker updates without diving into the backend.
Generalize and Create Query Program Endpoints
New endpoints support the generalization and creation of query programs, enabling more flexible query definitions and execution. This enhancement facilitates dynamic query management, allowing users to adapt and extend their querying capabilities quickly.
Enhancements & UX Improvements
Improved Expression Slots in Query System
Experience a smoother querying process with updates to expression slots. This comprehensive overhaul enhances syntax handling and allows for more complex query constructions, improving the overall efficiency and flexibility of data queries.
API Endpoints Enhancement
Newly added API endpoints extend the functionality of your application, providing more structured and accessible data interaction methods. These changes support better integration and scalability of your services.
Bug Fixes
Resolved issues with column limits by reclassifying LimitsT as a more appropriate StrEnum, improving data model flexibility and stability.
Addressed problems with text-based query plans that hindered query clarity. This feature has been temporarily removed to enhance the overall query generation process.
These updates aim to streamline your workflow, enhance the usability of APIs, and ensure a more robust and flexible data management experience.
Dec 8, 2024
Enhanced Data Handling and Query System Improvements
Feature Updates
Default Values Integration in Query Programs
Introducing default values for slots in query programs enhances the robustness and reliability of code execution. This new feature ensures that all slots are pre-filled with sensible defaults, minimizing errors and improving execution consistency.
New API Endpoint for Query Programs
A new API endpoint now allows retrieval of APIs by queryprogram_id, streamlining access and integration. This update simplifies backend processes, making it easier to manage and interact with specific query programs.
Enhancements & UX Improvements
Improved Query Techniques and Documentation
The query system now boasts enhanced techniques, including improvements to the rank method and support for more complex operations like grouping. Documentation updates, including the relocation of 'technique' comments, enhance guidance and usability for developers working with the system.
Simplified Expression Handling
Significant changes to how expressions are serialized and deserialized in query programs now allow for more efficient processing and reduced ambiguity. This improvement aids in maintaining clarity and precision within the codebase.
Streamlined Preprocessor and Module Loading
Enhancements to the preprocessor ensure better string extraction with correct handling of quotes, while module loading in QueryProgram has been centralized to improve maintainability and performance.
Bug Fixes
Addressed issues with slot replacement in functions from loaded modules, ensuring accurate execution.
Corrected the data model by removing the unused 'dataset_name' field, resolving related errors.
Fixed preprocessor string handling to properly decode escape sequences and strip surrounding quotes, enhancing data processing reliability.
Developer Experience
Schema Generation Advancements
Refinements in schema generation now provide clearer data insights through the addition of 'limits' to data columns. These changes also optimize data sampling methods, improving the robustness and accuracy of data handling processes.
Query Library and Example Enhancements
New functions for event progression and conditional execution have been added to the query library. These enhancements improve the flexibility and functionality of query operations, offering developers more tools to handle complex data scenarios effectively.
This week's updates focus on reinforcing the core functionality of our query systems and enhancing the overall developer experience with more intuitive interfaces and robust data handling capabilities.
Dec 1, 2024
Expanded API Capabilities and Enhanced Query Processing
Feature Updates
Comprehensive API Management with CRUD and Dynamic Documentation
Manage your APIs more effectively with newly implemented CRUD operations for API models and endpoints. Enjoy seamless integration with dynamic OpenAPI specs and live API documentation, ensuring clarity and ease of use for developers.
Advanced Query Programs with Entity Linking and Result Planning
Enhance your query processing by linking queries to data models, allowing for improved recognition and processing. The new entity linking functionality and result plan prologue feature give queries a structured approach, making data insights more accessible.
Enhancements & UX Improvements
Structured Data Handling and Schema Refinement
Experience improved data alignment with the introduction of StructuredData models, replacing the older schema object. This change enhances data integrity and supports better alignment with data models, streamlining data operations.
Flexible Query Expressions and Auto-Update Model Feature
The expr method in QueryProgram now accepts additional keyword arguments, offering more flexibility. Additionally, all models now automatically update with changes in the Prisma schema, ensuring your data is always current and accurate.
Bug Fixes
Resolved issues with JSON compatibility in QueryProgram formats, ensuring smoother data exchanges.
Fixed data processing errors by converting NumPy arrays to Python lists, preventing potential crashes.
Corrected the calculation logic in end-to-end tests, enhancing the reliability of test results.
This update brings significant improvements to API management, query flexibility, and data handling. Developers can now leverage enhanced tools and features for more effective and efficient project management.
Nov 24, 2024
Enhanced Query Functionality and Structured Output Support
Feature Updates
Structured Output in LLM Responses
Our latest update enriches the LLM's capabilities by supporting structured outputs, allowing for more organized and meaningful responses. This enhancement introduces a new DataModel for improved data representation and clarity. Developers can now benefit from better error handling and structured data management, making interactions with the system more robust and reliable.
Comprehensive Query System Overhaul
Experience a revamped query system with a streamlined dataline package. This overhaul cleans up obsolete code and introduces a more intuitive approach to handling queries, ensuring a smoother user experience and more efficient data processing.
Enhancements & UX Improvements
Improved Query Examples and Annotations
We've refined our query examples to make them more illustrative and added better annotations for DataFrame methods. These improvements help users understand method returns and leverage new methods for determining DataFrame characteristics like emptiness, width, and height.
Query Preprocessing Enhancements
The QueryPreprocessor now intelligently replaces slots with descriptive labels, enhancing the readability and maintainability of queries. This change ensures that the query processing is not only accurate but also easily understandable by users.
Bug Fixes
Fixed incorrect query generation involving SUM, MIN, and MAX operations by improving documentation to guide better query formulations.
Resolved a bug in the DataFrame method implementation to ensure all necessary operations like the mean are supported.
Fixed message formatting issues in dataline prompts to ensure consistent and correct message delivery.
Nov 17, 2024
Enhanced Query Generation and Improved Deployment Flexibility
Feature Updates
Advanced Query Generation with New Endpoints
We've upgraded our system to leverage the OPENAI model for enhanced functionality. A new endpoint now facilitates asynchronous query generation for datasets and dataline models, significantly improving the efficiency and speed of data processing tasks.
Comprehensive CLI for Server Management
Introducing a robust command-line interface (CLI) for managing Infactory servers. This update enhances usability by allowing users to manage stacks instead of profiles, complete with CRUD operations for better stack management. Enjoy a new launcher UI for interactive stack configuration and deployment, along with improved stack management configurations for seamless user experience.
Enhancements & UX Improvements
Streamlined Kubernetes Deployment
Deployment to Kubernetes has never been easier. We've integrated code updates for seamless deployment to Kubernetes environments, including auto-applying schema changes upon container creation. This ensures smoother transitions and more efficient resource management across multi-platform environments.
Flexible Multi-Platform Environment Setup
With the introduction of Docker and Docker Compose in our staging setup, building and running multi-platform environments has become more straightforward. This change offers greater flexibility and aligns with modern deployment practices.
Bug Fixes
Resolved an issue where default JSON configurations were not being parsed correctly, ensuring data integrity and application stability.
Developer Experience
Improved Endpoint Management
Small but impactful improvements to our API endpoints now include project ID filtering and enhanced data lineage details. These enhancements provide developers with more granular control and insights into data handling, promoting more efficient data management practices.
Nov 10, 2024
Streamlined Data Management and Schema Enhancements
Feature Updates
Enhanced Data Line and Organization Management
Introducing the capability to add project_id to data lines, allowing for more precise project tracking. Additionally, the clerk_org_id is now optional when creating an organization, providing greater flexibility in organizational management. This update streamlines the process of associating data lines with specific projects, benefiting project managers and data analysts.
Refined Project and Organization Schemas
We've cleaned up project and organization schemas to improve data handling and integrity. This includes adding a deleted_at field to the patch endpoint and a filter for the get endpoint, which makes it easier to manage and query archived data. This refinement enhances the clarity and usability of project data for administrators and developers.
Enhancements & UX Improvements
Consistent Endpoint API
Our API has been refined for consistency, ensuring that argument processing is now aligned with input expectations. This makes API integration smoother and reduces potential errors in data handling, which is particularly beneficial for developers working with our tools.
Improved Dataline Examples
New example data line files have been added to ensure accurate generation and fix previous issues with GeneralColumnT's. This update helps developers and data scientists to better understand and utilize data line formats, leading to improved data processing workflows.
Bug Fixes
Resolved a regression issue where the 'ask dataline' feature was not emitting the correct number of outputs. This fix ensures that the feature delivers reliable results, supporting data analysts in obtaining accurate data insights.
Nov 3, 2024
Enhanced Data Handling and Query Optimizations
Feature Updates
Rank Query Step: Flexible Data Ranking
Introducing a new Rank Query Step that allows for customizable data ranking. You can now compute rankings on specified columns with optional grouping, making it easier to derive insights from complex datasets. This update is particularly beneficial for users who need to analyze data trends and patterns efficiently.
Improved Dataline Generation with Comprehensive Examples
We've enhanced our dataline generation capabilities by replacing the billionaire dataset with a more comprehensive USA cities dataset. This change offers a broader coverage of supported data types, providing a more robust example for leveraging LLMs in data generation tasks.
Enhancements & UX Improvements
Migration to AWS S3: Streamlined Data Management
Say goodbye to Git LFS dependencies! We have transitioned to AWS S3 for cloud storage, enabling seamless separation of code and data. This improvement facilitates better data management and accessibility, especially in Kubernetes environments.
Query Calculations: Better Performance and Accuracy
We've revamped our query calculations by removing Dask dependencies and exclusively using Pandas for DataFrame operations. This shift enhances both the performance and reliability of data processing tasks. Additionally, improvements to our merge and aggregation algorithms ensure faster and more accurate query results.
Developer Experience
Refactored Tool Endpoints for Greater Flexibility
Our tool endpoints have undergone a significant refactor, improving their implementation and testing processes. This update provides developers with a more streamlined workflow for testing and deploying tool APIs, enhancing overall productivity and code clarity.
Oct 27, 2024
Streamlined Query Systems and Enhanced API Management
Feature Updates
Expanded API Endpoints for Better Tool Management
Our API has been expanded to include new routes for managing tools, complete with improved error handling and versioning. Users can now benefit from detailed API documentation and a new logo endpoint to enhance brand visibility.
Methodical Query System Overhaul
The query system has been refined with the introduction of new QuerySteps like Merge, Percentage, Pick, and DIFF. These additions facilitate more complex queries and improve the handling of sub-results within your data analysis workflows. The system now also supports intuitive merging of DataFrame columns, enhancing query accuracy and efficiency.
Enhancements & UX Improvements
Dataset Collection and Management
We've pruned and expanded our dataset offerings with updates to the usa_covid_vaccinations.csv and the addition of the baby_names.csv dataset, making data management more comprehensive and easier to navigate.
Improved Query Syntax
Significant improvements in query syntax have reduced the character count needed for expressions by over 30%, enabling faster query formulation. The use of operator overloading and streamlined class naming conventions make the query process more intuitive and efficient.
Bug Fixes
Addressed a critical bug in the ensure_dask_df call, improving the reliability of data processing functions.
Fixed an issue where datasets without an existing ID column were causing failures. A new mechanism ensures unique key generation, preventing disruptions in data transformations.
Developer Experience
Docker and Deployment Enhancements
The Docker Compose files have been updated to align with Kubernetes staging deployments. This update allows seamless backend and frontend service operations via Docker Compose, setting the stage for future Kubernetes integrations.
Enhanced Testing Framework
Introduced a robust testing framework that includes accuracy tests and comprehensive end-to-end tests across multiple datasets. This ensures the reliability and correctness of query outputs, providing confidence in system operations.
By focusing on these improvements, we aim to deliver a more intuitive and powerful data management experience while ensuring stability and reliability across our systems.
Oct 20, 2024
Enhanced Query System and Streamlined Data Management
Feature Updates
Unified Query Aggregation
All aggregation functions such as average, count, max, min, and sum are now streamlined through a single AggregateColumnsStep. This update simplifies query management and enhances consistency across data processing tasks.
Improved Query Grouping Capabilities
Leverage advanced expression grouping with the new CalculateRowStep, which introduces sophisticated date-time calculations like truncating to hours and minutes, offering more granular data insights.
Expanded Dataset Collection
Introducing a refined dataset lineup, including faang_stocks.csv and nyc_taxi_rides.csv, enhancing your data exploration and analysis capabilities. Obsolete datasets have been removed, ensuring a cleaner, more relevant data environment.
Enhancements & UX Improvements
Workspace Experience Enhancements
Enjoy a smoother command entry and history functionality within your workspace, improving the overall user experience and efficiency during data interactions.
Diverse Workspace Example Updates
Example prompts have been updated to include a wider variety of random workspace names, enriching the diversity and relevance of your workspace scenarios.
Performance & Reliability
Transition to Dask for Query Processing
The query system now utilizes Dask, optimizing performance for large data operations and aligning with best practices for distributed computing.
Codebase Clean-up and Optimization
Significant code clean-up efforts have been made to remove unnecessary components and optimize Dask client usage, aligning more closely with Dask's architecture for better performance and reliability.
Bug Fixes
Resolved bool transformation issues within the transform_data tool, improving data processing accuracy.
Removed the pyicu dependency, transitioning to Pendulum for date management, ensuring more reliable date handling and reducing dependency overhead.
These updates collectively enhance the system's efficiency, usability, and performance, providing users with a more robust and intuitive data management experience.
Oct 13, 2024
Streamlined Deployment and Enhanced Code Organization
Feature Updates
Local Deployment Services: Simplified Setup with Docker Compose
Introducing a robust local deployment solution with the addition of docker-compose.yml and docker-compose-client.yml files. This setup allows for seamless local environment configuration, complete with integrated services like pgAdmin and PostgreSQL, making it easier for developers to manage and deploy applications locally.
Enhancements & UX Improvements
Dev Repository Cleanup: Improved Structure and Clarity
We have reorganized our development repository to enhance code clarity and maintainability. Key improvements include:
A refined folder structure for better navigation.
Transitioning to Poetry for dependency management over pip, streamlining package handling.
Enhanced build and deployment scripts for more efficient workflows.
Obsolete File Removal: Cleaner Code Base
Legacy and obsolete files have been pruned from the codebase, resulting in a cleaner and more efficient environment. This cleanup includes the relocation of set-clang-alternatives.py to a more appropriate directory, ensuring better script organization.
Bug Fixes
Endpoint Class Hierarchy Correction
Addressed a critical issue with the endpoint class hierarchy that affected data processing. The fix ensures that data flows correctly through the system, maintaining integrity and reliability across services.
These updates focus on improving the development experience by simplifying deployment processes, enhancing code organization, and ensuring the stability of key application components.
Oct 6, 2024
Enhanced Infrastructure and Improved Documentation Clarity
Feature Updates
Dataline Dynamic Loading Enhancements
We have restructured the server infrastructure to enable dynamic loading capabilities for Dataline, paving the way for more efficient workshop development. This update will facilitate faster deployment and greater flexibility in managing data processing tasks, benefiting developers and system architects who rely on seamless data integration.
Bug Fixes
Spark Version Upgrade and Documentation Clarity
We've upgraded Spark to the latest versions, ensuring compatibility and improved performance. Additionally, the README has been clarified to provide better guidance, and we've removed hard-coded paths for temporary folders within the Docker setup. These changes enhance the ease of setup and ensure a smoother developer experience, especially for those setting up development environments or troubleshooting configurations.

